

Create a Synthetic Dataset Using Llama 3.1 405B for Instruction Fine-Tuning
Using the giant Llama 3.1 405B and Nvidia Nemotron 4 reward model to create a synthetic dataset for instruction fine-tuning.


Data is the heart of AI and while it is a valuable asset, we know how challenging and costly it is to develop high-quality datasets. A well-curated and filtered dataset can make up for a lack of complexity in a model. This is also the case with Large Language Models where smaller-sized models have shown to outperform bigger LLMs by leveraging good data.
In this article, we will explore how to use Llama 3.1 405B to create a synthetic dataset of git commands in natural language. I will show how you can use this 405B beast without running tens of GPUs in parallel. After having an initial dataset of instructions and responses, we will use Nvidia’s Nemotron 4 as a reward model to filter out any bad prompt/response pairs. Finally, we will push this dataset to HuggingFace for later fine-tuning of our LLM.
This will be fast, free, and will leave you much in control.
I will keep this post concise and knowledge-packed, so make sure to read through the end and familiarize yourself with this essential skill.
🦙 Why Llama 3.1
Meta has gained a firm foothold with the release of their latest family of LLMs, Llama 3.1. The new family includes an upgraded version of the previous 8B and 70B models with increased reasoning abilities and a giant 405B model.
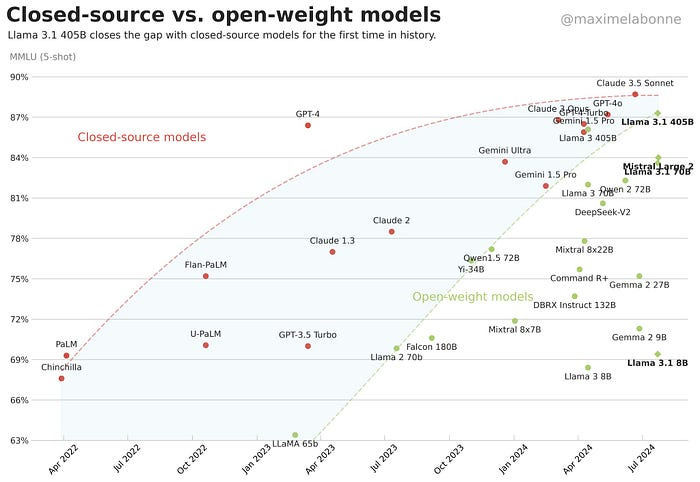
Llama 3.1 405B isn’t just impressive in terms of the sheer scale, but also by closing the gap between closed-source and open-source models, more than ever before (above figure).
This capability of the 405B model makes it ideal for some of the most important and nuanced workflows, such as Retrieval-Augmented Generation (RAG), supervised fine-tuning (SFT), and most importantly synthetic data generation.
Why Synthetic Data?
Synthetic data is created using an artificial model by reproducing the characteristics and features of real-world data. At some point, you will need to work with it when you need more data than you have.
Our example of a dataset of git commands in natural language can show this perfectly. If we want to create an application that takes as input, what the user needs and then suggests the right git command for it, then at the heart of this application we will need an expert LLM. We could use GPT-4o or Claude and will most likely get good results. But there is the problem of the cost. So the alternative would be to fine-tune a Small Language Model (SML) such as Llama 3.1 8B or Gemma 2 2B (which I will get to in a later post).
And guess what we need for fine-tuning… Data!
Since I didn’t find the right dataset for this task, we are left with only one solution: to create our dataset synthetically using Llama 3.1 405B.
🛠️Building the Dataset
To build a synthetic dataset using AI, we will use the following outline. You can choose any other LLMs from what I have chosen.

Setting Up the API Key
We will use the Nvidia NIM API to leverage these big LLMs without the hassle of running them locally. Running a model like Llama 3.1 405B on the device would normally require multiple H100 GPUs and unless you work in an organization with such resources, you need to use external APIs.
To access your free Nvidia credits, go to Llama 3.1 on Nvidia NIM, and click on Get API Key. This is what we will use in our code or a .env file. Once we have the API, we can set up our connection to the Nvidia server to use the models remotely.
client = OpenAI(
base_url="https://integrate.api.nvidia.com/v1",
api_key=os.environ["NVIDIA_API_KEY"]
)
MODEL = "meta/llama-3.1-405b-instruct"Generate Subtopics
Ideally, we like our dataset to cover various scenarios and situations as much as possible. One way to ensure this is to define subtopics and ask Llama 3.1 to provide instructions/response pairs for each of the subtopics. We can choose these subtopics ourselves or leave it to the LLM to decide. I took the second approach in the following code snippet.
n_subtopics = 5
TOPIC_GENERATION_PROMPT_TEMPLATE = """\
I want to create a synthetic dataset of natural language and Git commands. Based on this context, give me {n_subtopics} subtopics
to cover what needs to be covered when working with Git.
The list must be without numbers, and without any description of the subtopics. The subtopics should be separated by a comma. There must be no other text than the list.
"""
def generate_subtopics(client, n_subtopics):
prompt = TOPIC_GENERATION_PROMPT_TEMPLATE.format(n_subtopics=n_subtopics)
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "user",
"content": prompt}
],
temperature=0.2,
top_p=0.7,
)
return response
responses = generate_subtopics(client, n_subtopics=n_subtopics)
print(responses.choices[0].message.content)The LLM suggests five topics: Branching, Merging, Committing, Remote repositories, and Resolving conflicts. It seems like a fair selection of subjects to cover.
Generate Instructions
Having five subtopics of working with Git, we need Llama 3.1 to generate a set of instructions (or prompts) regarding each of the subtopics. I have asked for one hundred instructions per topic, so ideally, I should get 500 prompts.
One thing to keep in mind is that when asking for N number of instructions: it is rare that the model would return exactly as many as you want, even a big model like this.
Eventually, I got a total of 335 instructions for 5 subtopics, which is very different from 500. There are methods to ensure this doesn’t happen but for the sake of simplicity, we won’t dwell on this.
n_instructions = 100
INSTRUCTION_PROMPT_TEMPLATE = """\
The objective is to create a dataset of user instructions in natural language that should be returned by Git commands.
Given a topic in Git, generate {n_instructions} possible concise instructions that could be given to an AI assitant about that topic.
Write some of these instructions as if given by someone with limited knowledge of Git terminologies and knowledge,
like a beginner programmer. Your response should be in a list format.
The topic is: {sub_topic}
The list must be without numbers. The questions/instructions should be separated by a newline character. There must be no other text than the list.
"""
subtopic_list = responses.choices[0].message.content.split(",")
def generate_instructions(client, sub_topic, n_instructions):
print(f"Generating Instructions for {sub_topic}.")
prompt = INSTRUCTION_PROMPT_TEMPLATE.format(sub_topic=sub_topic, n_instructions=n_instructions)
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "user",
"content": prompt}
],
temperature=0.2,
top_p=0.7,
)
return response.choices[0].message.content
def instructions_generator(client, subtopic_list, n_instructions):
instruction_list = [generate_instructions(client, subtopic, n_instructions) for subtopic in subtopic_list]
return instruction_list
instruction_list = instructions_generator(client, subtopic_list, n_instructions)
instruction_list_formatted = []
for instruction_set in instruction_list:
instruction_list_formatted.extend([instruction.strip() for instruction in instruction_set.split("\n") if instruction])
print(instruction_list_formatted)Here are some examples of the generated instructions:
'Make a branch that I can merge back into the main branch',
'I want to make a branch that is based on an older version of the code',
'Can you show me a log of all commits that have been made to the repository this year?',Response Generation
For each of the provided instructions, we will also ask for a response. As you can see in the following code snippet, I have specifically asked my responses to be on-topic, informative, and concise. By the end, I will have a list of instruction and response pairs.
RESPONSE_PROMPT_TEMPLATE = """\
Given an question/instruction related to Git, generate a response that could be given.
Keep the response on-topic, informative, concise.
The user prompt is: {instruction}
"""
def generate_responses(client, instruction):
prompt = RESPONSE_PROMPT_TEMPLATE.format(instruction=instruction)
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "user",
"content": prompt}
],
temperature=0.2,
top_p=0.7,
max_tokens=1024,
)
return response.choices[0].message.content
def response_generator(client, instruction_list):
response_list = [generate_responses(client, instruction) for instruction in instruction_list]
return response_list
instruction_response_list = response_generator(client, instruction_list_formatted)
instruction_response_pair_list = []
for instruction, response in zip(instruction_list_formatted, instruction_response_list):
instruction_response_pair_list.append(
{
"instruction": instruction,
"responses": response,
}
){"instruction": "Can you make a branch for me and name it \"new-feature\"",
"responses": "To create a new branch named \"new-feature\", you can use the following Git command:\n\n`git branch new-feature`\n\nThis will create a new branch with the specified name. If you want to switch to the new branch immediately, you can use:\n\n`git checkout -b new-feature`\n\nThis will create the branch and switch to it in one step."}Filtering Responses with Nemotron 4
Even though we have our instruction/response pairs, not all of the responses are high-quality. They may be verbose, complex, or false. This is where Nvidia’s Nemotron 4 340B Reward model comes into play. It is made exactly for our use case, as according to Nvidia, it “can be used as part of a synthetic data generation pipeline to create training data that helps researchers and developers build their own LLMs.”

We will give each one of our instruction/response pairs to Nemotron 4, and receive five scores ranging from 0 to 4. These five scores are helpfulness, correctness, coherence, complexity, and verbosity. To use the model, I will first define a simple function to feed an instruction and a response to the model and receive the five scores in the shape of a dict.
def get_scores_from_response(score_response_template):
logprobs = score_response_template.choices[0].logprobs.content
score_dict = {}
for score in logprobs:
score_dict[score.token] = score.logprob
return score_dict
def get_response_and_scores(client, model, question, response_content):
messages = [
{
"role": "user",
"content": question
},
{
"role": "assistant",
"content": response_content
}
]
response = client.chat.completions.create(
model=model,
messages=messages,
)
scores = get_scores_from_response(response)
return scoresAfter we have a score for each of the rows in our dataset, we can filter the dataset using each of the five provided criteria. I will filter out bad responses based on helpfulness and verbosity, as I want to keep my responses concise and informative.
helpfulness_THRESHOLD = 3
verbosity_THRESHOLD = 2.5
synthetic_data = [data for i, data in enumerate(synthetic_data)
if not (score_list[i]["helpfulness"] < helpfulness_THRESHOLD or
score_list[i]["verbosity"] > verbosity_THRESHOLD)]Push the Dataset to HuggingFace
Finally, once you have the finished dataset, it’s a good practice to push it to HuggingFace to use it later or to share it with other developers. To do this, first log in to HuggingFace and provide a token, following the provided link on the login page.
from huggingface_hub import login
login()Then you can load the saved dataset and upload it on your HuggingFace page.
with open(f'synthetic_data_filtered.jsonl', 'r') as f:
data = [json.loads(line) for line in f]
dataset = Dataset.from_list(data)
dataset_dict = DatasetDict({"train": dataset})
dataset_dict.push_to_hub("hesamsheikh/git-prompt")Congrats 🏆! So far you have been able to use Llama 3.1 to create a dataset of instructions and responses, and Nemotron 4 to refine the dataset and filter out bad responses. In the end, we saw how easy it is to push the dataset to HuggingFace with no effort. Create Synthetic Dataset from 1 TOPIC for Instruction Finetuning is also a great inspiration for this article and I would suggest you watch it if you like this topic.
Here is also the repository where you can find the complete code I have used. Don’t forget to star ⭐the repo if you check it out.
Creating Synthetic Dataset Using Llama 3.1 405B and Nemotron 4
Thank you for reading through the article! Please share your opinions and suggestions if you think any modifications are required.
Let’s Connect!
Subscribe for FREE to be notified of new articles! You can also find me on LinkedIn and Twitter.