

LoRA Learns Less and Forgets Less
We will go through LoRA (Low-Rank Adaptation of Large Language Models), what it is, and the interesting properties of LoRA when compared to Full Fine-Tuning


LoRA is one of the ABCs of working with LLMs. To intuitively know what LoRA does, why it is important in fine-tuning, and, most importantly, when not to use LoRA is an essential topic to know by heart before tweaking the weights of your model.
In this article, we will walk through how traditional fine-tuning works and its shortcomings, what LoRA is, and some interesting properties of it.
Full Fine-Tuning vs Parameter-Efficient Fine-Tuning
As the size of Large Language Models (LLM) increases to hundreds of billions, fine-tuning these beasts becomes a challenge. Traditionally, to fine-tune a model, we would need to update all of the model parameters. This is also known as Full Fine-Tuning (FFT). A close overview of how this method works can be seen in the diagram below.
There are a few trivial problems with this approach. First, the computational cost and resource requirements for FFT are substantial, as updating every parameter requires significant processing and memory. Secondly, with a method like FFT, there is a risk of catastrophic forgetting, where the model forgets previously learned information as it over-learns the new data.
A family of methods called Parameter-Efficient Fine-Tuning (PEFT) emerged in response to this. PEFT reaches close accuracy compared to FFT, with just modifying a small percentage of parameters (even 1% in some tasks).
The result? with PEFT, fine-tuning will need much less computation and time, plus reducing the risk of overfitting.
LoRA: Low-Rank Adaptation of Large Language Models
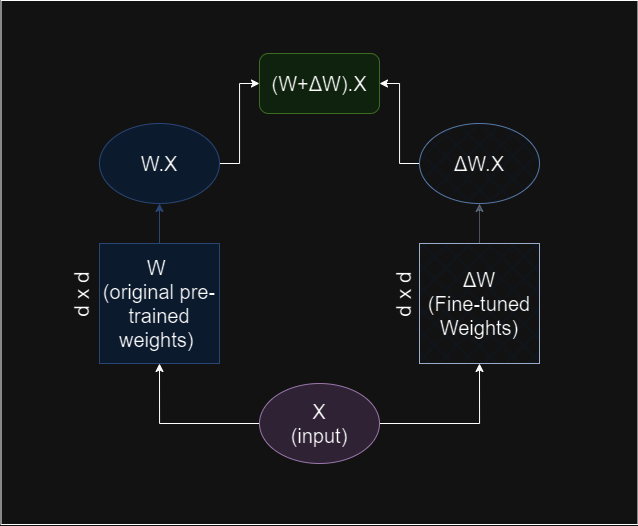
A popular PEFT method is LoRA: Low-Rank Adaptation of Large Language Models. The method stands on the pillar of one hypothesis: the weight change matric ΔW can be represented in lower dimensions. In other words, the rank of ΔW is low. This is known as the Intrinsic Rank hypothesis.

ΔW is decomposed into the product of two smaller matrices, reducing the number of parameters that need to be updated during fine-tuning. Let’s assume ΔW is a 4096 by 4096 square matrix. We continue to decompose it into two matrices of shape 4096 by r and r by 4096 (r being a hyperparameter we choose for training that controls the trade-off between efficiency and performance).

Now, instead of tuning 4096 * 4096 = 16,777,216 parameters, we will only need to tune 2 * 4096 * r parameters. If we choose r to be, say 256, that leaves us 2,097,152 parameters with LoRA, effectively 0.125 of the parameters we needed to work with otherwise.
LoRA and Low-Rank Constraint
LoRA also comes with shortcomings. A recent paper, “MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning”, explores a new LoRA-like method and, while doing so, points at a pitfall of LoRA. (I will go in-depth into MoRA in a future article so make sure to follow)

The inherent constraint of keeping updates low-rank means that LoRA may fall short in adapting to completely new domains or capturing complex knowledge. This is especially true in scenarios where the model needs to significantly deviate from its initial training to adapt to new types of data or tasks.
Understanding MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning
The property that makes LoRA not fall into catastrophic forgetting also limits it from drastic weight updates and adapting to new domains.
LoRA Learns Less and Forgets Less
Another paper, “LoRA Learns Less and Forgets Less”, argues that by training fewer parameters, LoRA acts as a regularize that forces the fine-tuned model to remain close to the prior-learned data.
LoRA as a Regularize

LoRA is found to be a stronger regularizer compared to traditional methods like weight decay and dropout. This trait of LoRA prevents the loss of generalization on tasks that the model was originally trained on, which is a known issue with the more aggressive methods of fine-tuning.
LoRA vs. FFT

The authors of the paper fine-tune models with LoRA and FFT in two domains: programming and math. As shown in the figure above, LoRA drastically falls below FFT in Coding tasks (but less in math). This gap also increases with the growing number of tokens to learn.
Note that the gap is much bigger in continued pretraining (≈10B unstructured tokens) compared to instruction fine-tuning (≈100K prompt-response pairs). This highlights that LoRA is much less effective in learning a new domain when compared to changing the tone and behavior in the same domain.
The conclusion? LoRA Learns Less and Forgets Less.
🌟 Join +1000 people learning about Python, ML / MLOps / AI, Data Science, and LLM. follow me and check out my X/Twitter, where I keep you updated Daily.
Thanks for reading,
— Hesam