



Understanding Buffer of Thoughts (BoT) — Reasoning with Large Language Models
A new prompting tool for complex reasoning, compared with Chain of thought (CoT) and Tree of Thought (ToT)


Squeezing proficiency in complex reasoning tasks and avoiding hallucinations remains a major research topic in Large Language Models (LLMs). Despite the effort, LLMs need help with generalized reasoning capabilities. Traditional methods such as Chain-of-Thought (CoT) or Tree-of-Thought (ToT) often require multiple assumptions or numerous back-and-forth prompting which means intensive computation.
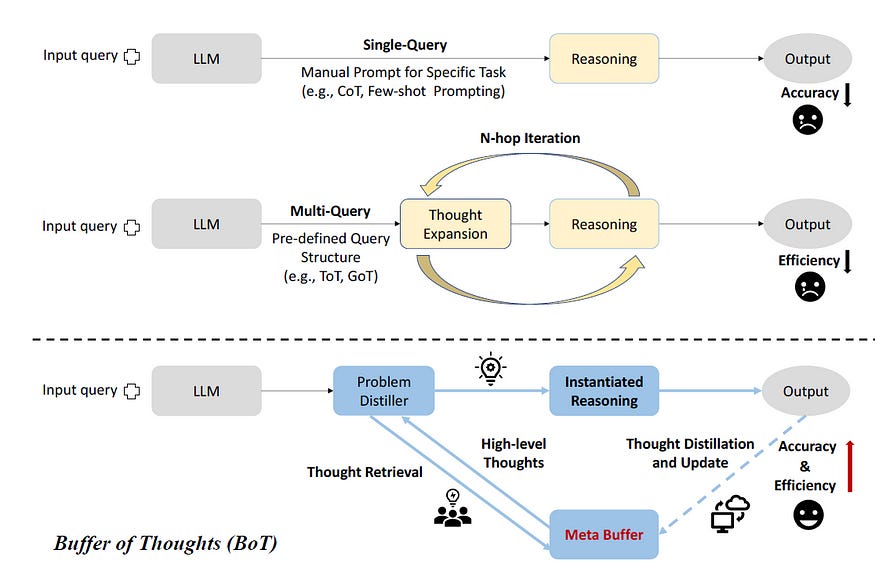
The new proposed method in the paper, Buffer of Thoughts: Thought-Augmented Reasoning with Large Language Models [1], combats these limitations with a dynamic, adaptive repository of high-level thought templates called meta-buffer. In BoT, once the user presents a new problem, it is first simplified and analyzed to extract key elements, which then guide the retrieval of a relevant thought template from a dynamic dataset. This allows adaptive and efficient problem-solving through modified and complex reasoning patterns. According to the original paper, this is so effective that “Llama3–8B+BoT has the potential to surpass Llama3–70B model.”
BoT achieves efficient reasoning across problems that are similar to its templates as it:
(1) leverages previous solutions on new challenges,
(2) boosts efficiency by eliminating the need for multiple query iterations (as we see in Graph-of-Thoughts (GoT) or ToT), and
(3) dynamically updates its template repository to ensure it evolves as it encounters new tasks.
In this article, we will first go through the general outline of how BoT works, understand the function of each key part, and test the procedure with an example.
How does BoT work?
The general thought-augmented reasoning process (as shown in the figure below) starts with Problem Distillation, which analyzes and condenses the incoming task into essential elements and constraints and then creates a simplified problem statement.
This distilled information is then used to query the Meta-Buffer, a dynamic repository that contains high-level thought templates. From the thought templates, one that is most similar to the distilled problem is retrieved. Then, during the Instantiation Process, it is instantiated with specific requirements and information about the distilled problem.
Throughout this process, the Buffer Manager actively keeps an eye on the Meta-Buffer. Once it detects a new insight not included in the meta-buffer, Buffer Manager updates it to ensure a continual evolution of the thought template repository.
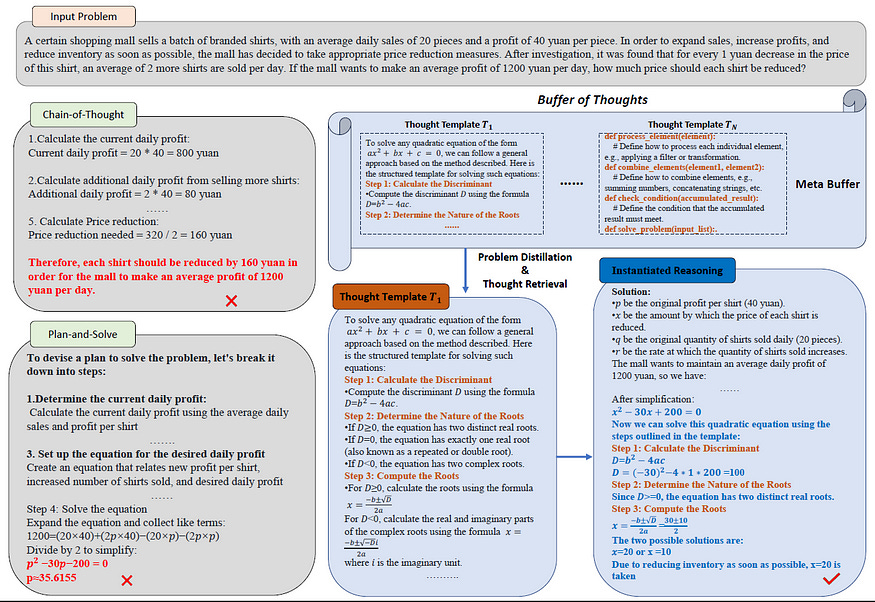
Let’s go through each of these key parts to gain a more detailed look:
Problem Distiller
Problem Distiller can be thought of as a preprocess on the input tasks in order to…
(1) extract essential information of the problem, and
(2) simplify complex tasks for a better search and retrieval of thought templates.
Problem Distiller takes the burden off of LLM to identify and extract vital information and constraints of the problem. This is done by a meta prompt ϕ:
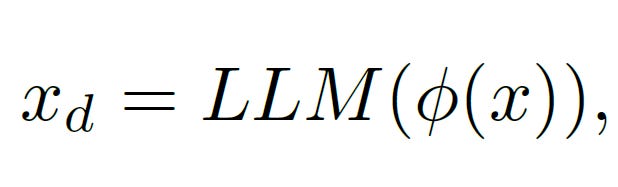
The prompt used by the authors to distill key information about a task is as follows:
[Problem Distiller]:
As a highly professional and intelligent expert in information distillation, you excel at extracting essential information to solve problems from user input queries. You adeptly transform this extracted information into a suitable format based on the respective type of the issue.
Please categorize and extract the crucial information required to solve the problem from the user’s input query, the distilled information should include.
1. Key information:
Values and information of key variables extracted from user input, which will be handed over to the respective expert for task resolution, ensuring all essential information required to solve the problem is provided.
2. Restrictions:
The objective of the problem and corresponding constraints.
3. Distilled task:
Extend the problem based on 1 and 2, summarize a meta problem that can address the user query and handle more input and output variations. Incorporate the real-world scenario of the extended problem along with the types of key variables and information constraints from the original problem to restrict the key variables in the extended problem. After that, use the user query input key information as input to solve the problem as an example.Meta-Buffer
The meta-buffer is a central database that stores high-level thought templates. These templates are high-level abstractions representing various problem-solving processes. The idea is that LLM can leverage past problems and insights to solve current challenges. The best part is that the Meta-Buffer dynamically updates to ensure new unseen problems are also included. The Meta-Buffer doesn’t enforce thought templates to follow a specific instruction.
Template Retrieval: Once a task is distilled, BoT would go through the thought templates and grab the one most similar to the task. This is done by calculating the embedding similarity between the task and the thought templates.
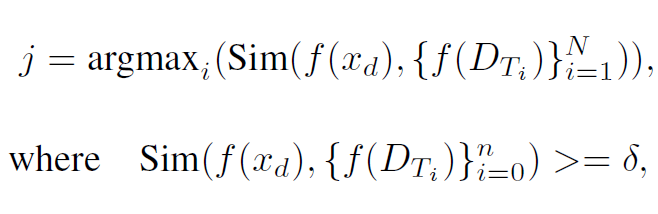
the retriever would calculate the similarity between the embedding of the input task f(xd), and the embedding of templates f(DTi ). This is only done if the similarity is above a certain threshold δ (0.5–0.7). If none of the thought templates have a similarity score with the task above the δ threshold, then the xd is identified as a new task. Depending on if the task is new or not, one of the two paths would be taken:
If the task is similar to one of the thought templates, the template would be instantiated with the distilled information using an instantiation prompt (which you can check in the paper). This instantiation process can be denoted as

If the task is new, a general thought template that is designed to address a broad set of problems is used. As the task is processed, the Buffer Manager observes and learns and potentially creates a new, more specific thought template and pushes it to the meta-buffer.
Buffer Manager
The Buffer Manager serves as a crucial player in maintaining and enhancing the meta-buffer. Based on the new insights and outcomes from the tasks that are solved, it updates the thought templates. Also, whenever a new or drastically different problem is solved, the buffer manager assesses whether or not to create a new thought template. This is to ensure thought templates remain to the point and are not redundant.
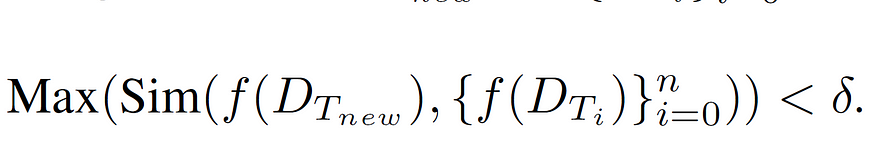
By employing the above formulation, the Buffer Manager checks whether or not the meta-buffer already has the necessary knowledge to tackle a problem.
BoT vs. Single-Query vs. Multi-Query
How does the BoT stand out compared to previous methods? The authors of the paper evaluate various methods on different datasets of various tasks, such as Data Understanding, Python Programming Puzzles, Multilingual Grade School Math (MGSM), etc. The results show a surprising advantage of BoT in almost all the tasks.
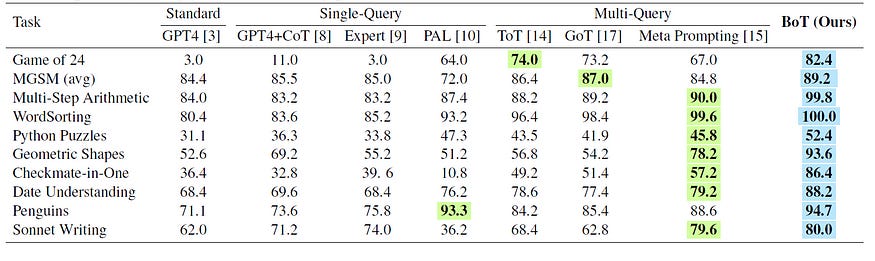
One of the key advantages of BoT is its efficiency — requiring only 12% of the computational cost on average when compared to multi-query prompting methods. This high computational cost and latency of multi-query methods such as ToT often renders them impractical in real-world use cases.
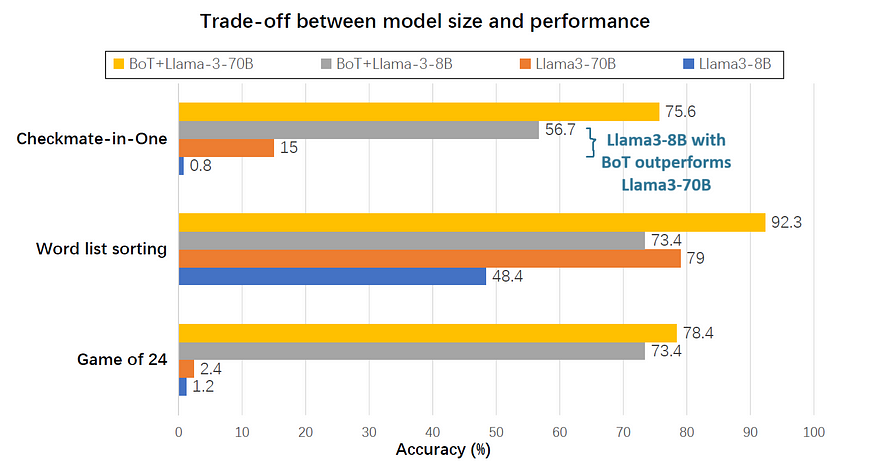
BoT+Llama3–8B has the potential to surpass single Llama3–70B model
Buffer of Thoughts in Practice
The demo code for Buffer of Thoughts is published on GitHub [2]. To test out the functionality in practice, I will use this method on a custom task: Word Reordering. In this task, the LLM must take a scrambled sentence, such as “Sam name is my”, and return a permutation of these words that is semantically meaningful, which in this example would be “my name is Sam”, (this is not a benchmark with baseline performance). Some examples of the scrambled sentences and the correct ones are as follows:
{"input": "<start> life plan and families to for social hospital workers outside with patients work the <end>",
"target": "<start> social workers work with patients and families to plan for life outside the hospital <end>"}
{"input": "<start> yield plant refers dry total to production biological matter <end>",
"target": "<start> biological yield refers to total plant dry matter production <end>"}
{"input": "<start> the bloodstream into alcohol from directly stomach goes the <end>",
"target": "<start> alcohol goes directly from the stomach into the bloodstream <end>"}I will also use the following user prompt to explain the task:
Reorder a list of words to make them semantically meaningful,
for example "Sam name is my" -> "my name is Sam".
Please provide only the reordered sentence without any explanations.
Start the ordered sentence with <start> and end it with <end>Provided this task, the BoT framework first distills my task and extracts the goal, the restriction, and how I would like my output along with other key information. The full procedure of BoT in detail, is the following terminal output:
User prompt:
Reorder a list of words to make them semantically meaningful, for example "Sam name is my" -> "my name is Sam". Please provide only the reordered sentence without any explanations. Start the ordered sentence with <start> and end it with <end>
Input:
<start> the melting in solid to gold leaf metals is achieve made by desired gold and mixing color other <end>
Distilled information:Meta distiller Respond:
Distilled Information:
1. Key information:
- Input: "<start> the melting in solid to gold leaf metals is achieve made by desired gold and mixing color other <end>"
2. Restriction:
- Reorder the list of words such that the sentence is semantically meaningful
- The output should begin with "<start>" and end with "<end>"
3. Distilled task:
- The task is to reorder the words to create a meaningful sentence from the provided mixed words inside the tags "<start>" and "<end>"
4. Python transformation:
(Optional, skip when Python tag is Not for Python) Input parameters:
input_sentence = "<start> the melting in solid to gold leaf metals is achieve made by desired gold and mixing color other <end>"
5. Answer form: (Optional, skip when there is no specific answer form)
The output sentence should be in the form of "<start> ... <end>"
**Note: The generation ends here. Do not show this message in your answer !**
Instantiated reasoning result: ```python
def ReorderWords(input_sentence):
# Remove the start and end tags, and split the sentence into words
words = input_sentence.replace("<start>", "").replace("<end>", "").strip().split()
# Tentative reordering to form a meaningful sentence
# Based on the context provided in the task, the following reordering seems logical
reordered_words = ["the", "melting", "in", "solid", "metals", "is", "achieved", "by", "mixing", "gold", "leaf", "and", "desired", "other", "color", "gold"]
# Join the words into a single sentence and add start and end tags
reordered_sentence = "<start> " + " ".join(reordered_words) + " <end>"
return reordered_sentence
# Input sentence provided in the task
input_sentence = "<start> the melting in solid to gold leaf metals is achieve made by desired gold and mixing color other <end>"
print(ReorderWords(input_sentence))
```
The result of code execution: <start> the melting in solid metals is achieved by mixing gold leaf and desired other color gold <end>Some of the examples of the reordered sentences using BoT:
{"input": "<start> life plan and families to for social hospital workers outside with patients work the <end>",
"result": "<start> Hospital workers work outside with social patients and plan to the families for life <end>\n"}
{"input": "<start> yield plant refers dry total to production biological matter <end>",
"result": "<start> Plant yield refers to total dry matter biological production <end>\n"}
{"input": "<start> the bloodstream into alcohol from directly stomach goes the <end>",
"result": "<start> the alcohol goes directly from the stomach into the bloodstream <end>\n"}Note, that the BoT repository I used is a demo code and lacks some of the features mentioned in the original paper, such as a general thought template, the dynamic updating of the Meta-Buffer, or finding the closest template embedding to the user task. These are important aspects of the framework and without them, we cannot conclude the performance of Buffer of Thoughts in practice.
Final Words
In conclusion, BoT shows promising results in both accuracy and efficiency in various domains and tasks. It’s an interesting approach to breaking down a reasoning problem into its fundamental restrictions and key information and building on top of previous solutions and templates to better formulate the task for an LLM to understand.
By addressing some of the limitations in other prompting techniques, Buffer of Thoughts allows LLM to have more complex thinking patterns, potentially making smaller lightweight models perform at the level of larger ones.
Allowing small LLMs to achieve results close to large LLMs is a key topic addressed in many of the current research papers. The goal is to employ various prompting and fine-tuning techniques to extract accurate AI outputs with low computation and cost.
Buffer of Thoughts is a novel and promising prompting framework that leverages a domain of techniques to guide LLM step by step, in a reasoning process. A complete practical implementation of the Buffer of Thoughts technique is yet to come, but in the meanwhile, test out the provided benchmarks in the demo GitHub repository [2].
If you have made it this far, consider subscribing:
🌟 Join +1000 people learning about Python, ML / MLOps / AI, Data Science, and LLM. follow me and check out my X/Twitter, where I keep you updated Daily.
Thanks for reading,
— Hesam
[1] Yang, L., Yu, Z., Zhang, T., Cao, S., Xu, M., Zhang, W., Gonzalez, J. E., & Cui, B. (2024). Buffer of Thoughts: Thought-Augmented Reasoning with Large Language Models. arXiv. Retrieved from https://arxiv.org/abs/2406.04271
[2] buffer-of-thought-llm, https://github.com/YangLing0818/buffer-of-thought-llm