

Understanding MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning
the math and intuition behind a novel parameter-efficient fine-tuning method


A recent, “MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning”, introduces a new method into the family of parameter-efficient fine-tuning (PEFT) and possibly a new alternative to the famous LoRA — Low-Rank Adaptation of Large Language Models.
In this article, we will walk through what problem MoRA is trying to solve, the basic idea behind it, and how it compares to LoRA.
Note: this article assumes you have comprehensive knowledge about LoRA. If this is a new concept, I would suggest reading this easy-to-understand article about LoRA and its drawbacks.
LoRA Learns Less and Forgets Less
Parameter-Efficient Fine-Tuning
Efficiently fine-tuning gigantic Large Language Models with hundreds of billions of parameters is an open area of research in machine learning. In the Full Fine-Tuning (FFT) method, we would need to update all the weights of a model in place.

This way of fine-tuning presents two major problems:
The computational cost and the needed time to fine-tune the whole corpus of a model are too significant to be practical.
By fully fine-tuning the model, we expose it to a known problem called “catastrophic forgetting”, meaning the model forgets previously learned information as it over-learns the new data.
Parameter-Efficient Fine-Tuning (PEFT) is a solution to the computationally intensive and time-consuming process of fine-tuning large language models. PEFT achieves comparable accuracy to full fine-tuning (FFT) by modifying only a small percentage of the model’s parameters, sometimes as little as 1% for certain tasks.
The result? with PEFT, fine-tuning will need much less computation and time, plus reducing the risk of overfitting.
The Idea of MoRA
MoRA’s idea is to take a different approach by using a square matrix M instead of the low-rank matrices used in LoRA. To work with this square matrix, MoRA reduces the dimensions of the input data to M (compress) and later increases the dimensions of the output of M (decompress). The big goal is to replace a high-rank matrix M rather than low-rank matrices in LoRA, and still maintain fine-tuning with very few parameters.
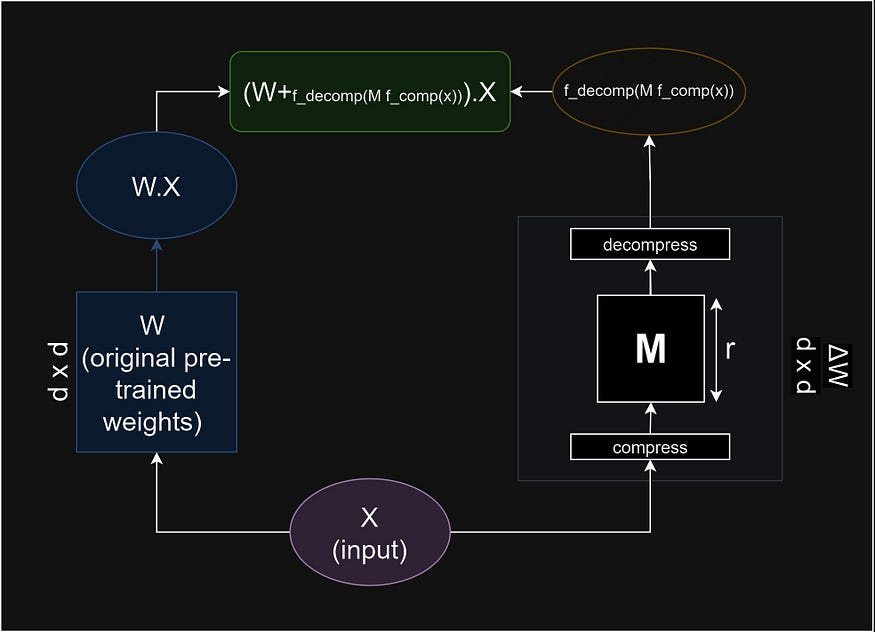
MoRA is still able to preserve the low number of parameters for fine-tuning as LoRA is. For example, given that the weight layer is 4096 x 4096 we would need to update 16,777,216 parameters with FFT. If we choose LoRA with r=8, this would result in 2 x (4096 x 8) = 65,536. With MoRA, if we choose M to be a 256 by 256 matrix, this would mean we need to tune 256 x 256 = 65,536 parameters, the same number as LoRA.
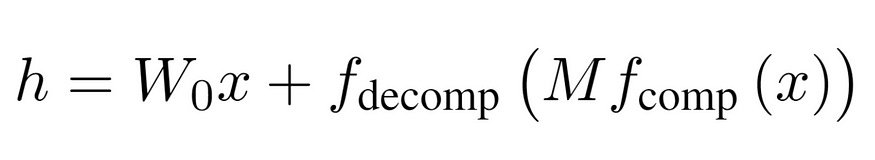
For the details of how to compress and decompress the data using f_decomp and f_comp, I would highly suggest reading the Method section of the paper.
The simplest method would be to truncate the dimension and subsequently add it back in the corresponding dimension (zero padding) as shown in the figure below. However, this would result in a significant loss of information during compression. Other methods such as Reshaping and Concatenation, or Row and Column Sharing are also introduced to mitigate the loss of the truncation method.

How Does MoRA Do?
LoRA is famous for being limited in capturing new information that is much different from the prior knowledge of the base model. This is fully explained in “LoRA Learns Less and Forgets Less”. LoRA underperforms much more in continued pretraining (unstructured tokens) compared to instruction fine-tuning (prompt-response pairs). This highlights that LoRA is less effective in learning a new domain when compared to changing the tone and behavior in the same domain, but this exact property of LoRA makes it immune to catastrophic forgetting and quality fine-tuning.

MoRA shows better performance in tasks that require the model to deviate drastically from the base model. Exactly where LoRA falls short, MoRA shows performance close to Full Fine-Tuning.
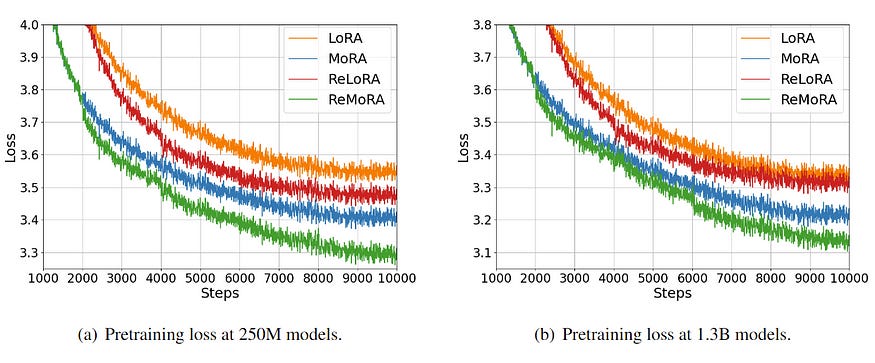
The authors of the original paper have evaluated various methods of Instruction Tuning, Mathematical Reasoning, and Continual Pretraining. MoRA performs surprisingly well on continuous pretraining while falling behind LoRA and its variations on the other two tasks.

It would be safe to assume MoRA is not a substitute for LoRA, but rather an extra PEFT tool tailored for more rigorous fine-tuning tasks. While LoRA is best used with changing tones and behavior of the model without changing the general domain, MoRA could be a better option to explore in cases where you need a domain shift or to go more extreme than LoRA.
🌟 Join +1000 people learning about Python, ML / MLOps / AI, Data Science, and LLM. follow me and check out my X/Twitter, where I keep you updated Daily.
Thanks for reading,
— Hesam