

What We Still Don’t Understand About Machine Learning
Machine Learning unknowns that researchers struggle to understand — from Batch Norm to what SGD hides


It is surprising how some of the basic subjects in machine learning are still unknown by researchers and despite being fundamental and common to use, seem to be mysterious. It’s a fun thing about machine learning that we build things that work and then figure out why they work at all!
Here, I aim to investigate the unknown territory in some machine learning concepts in order to show while these ideas can seem basic, in reality, they are constructed by layers upon layers of abstraction. This helps us to practice questioning the depth of our knowledge.
In this article, we explore several key phenomena in deep learning that challenge our traditional understanding of neural networks.
We start with Batch Normalization and its underlying mechanisms that remain not fully understood.
We examine the counterintuitive observation that overparameterized models often generalize better, contradicting the classical machine learning theories.
We explore the implicit regularization effects of gradient descent, which seem to naturally bias neural networks towards simpler, more generalizable solutions.
Finally, we touch on the Lottery Ticket Hypothesis, which proposes that large neural networks contain smaller subnetworks capable of achieving comparable performance when trained in isolation.
1. Batch Normalization
Introduced by Sergey Ioffe and Christian Szegedy in 2015 [1], batch normalization is a method to train neural networks faster and more stable. It was previously known that transforming the input data to have their mean set to zero and variance to one would result in a faster convergence. The authors used this idea further and introduced Batch Normalization to transform the input of hidden layers to have a mean of zero and a variance of one.
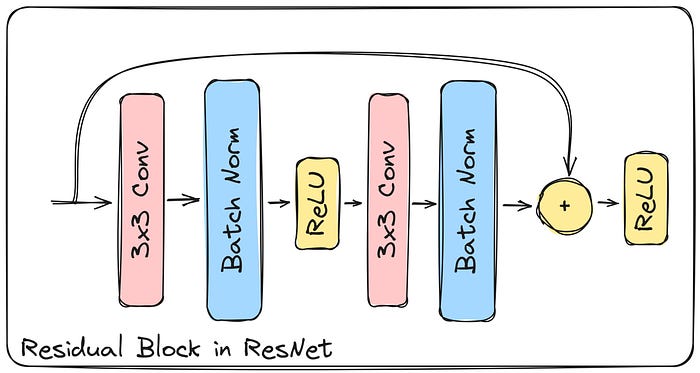
Since its introduction, the batch norm has become common in neural networks. One such example, among many, is its use in the famous ResNet architecture. So we could confidently say we are certain of how effective it could be.
An interesting research [2] on the effectiveness of Batch Norm showed that while training a full ResNet-866 network yielded 93 percent accuracy, freezing all the parameters and training only the parameters of the Batch Norm layers resulted in 83 percent accuracy — only a 10% difference.
Batch Norm is beneficial in three ways:
By normalizing the inputs to each layer, it accelerates the training process.
It reduces the sensitivity to initial conditions, meaning we need less careful weight initialization.
Batch Norm also acts as a regularizer. It improves model generalization and in some cases, reduces the need for other regularization techniques.
What We Don’t Understand
While the positive effect of the Batch Norm is evident, nobody quite understands the reason behind its effectiveness. Originally, the authors of the Batch Normalization paper introduced it as a method to solve the problem of internal covariate shift.
A heads-up about internal covariate shift is that you will find various definitions of it that don’t seem to be related at first. Here is how I would like to define it.
The layers of a neural network are updated during the backpropagation from the finish (output layer) to the start (input layer). Internal covariate shift refers to the phenomenon where the distribution of inputs to a layer changes during training as the parameters of the previous layers are updated.
As we change the parameters of the earlier layers, we also change the input distribution to the later layers that have been updated to better fit the older distribution.
Internal covariate shift slows down the training and makes it harder for the network to converge, as each layer must continuously adapt to the changing distribution of its inputs introduced by the update of previous layers.
The authors of the original batch normalization paper believed that the reason behind its effectiveness was that it mitigated the problem of internal covariate shift. However, a later paper [3] argued that the success of Batch Norm has nothing to do with internal covariate shift, but is due to smoothing the optimization landscape.

The figure above is taken from [4], which is not actually about Batch Normalization, but is a good visualization of how a smooth loss landscape looks like. However, the theory that the Batch Norm is effective due to smoothing the loss landscape has challenges and questions of its own.
Batch Norm Considerations
Due to our limited understanding of how Batch Normalization works, here is what to consider when it comes to using them in your network:
There is a difference between train and inference modes when using the Batch Norm. Using the wrong mode can lead to unexpected behavior that is tricky to identify. [5]
Batch Norm relies heavily on the size of your minibatch. So while it makes the need for a careful weight initialization less significant, choosing the right size of minibatch becomes more crucial. [5]
There is still an ongoing debate about whether to use Batch Norm before the activation function or after it. [6]
While Batch Norm has a regularizer effect, its interaction with other regularizations such as dropout or weight decay is not clearly known.
There are many questions to answer when it comes to Batch Norms, but research is still ongoing to uncover how these layers affect a neural network.
2. Over-Parameterization and Generalization

Big networks have challenged our old beliefs of how neural networks work.
It was traditionally believed using over-parametrized models would result in overfitting. Thus the solution would be either to limit the size of the network or to add regularization to prevent overfitting to the training data.
Surprisingly, in the case of neural networks, using bigger networks could improve the generalization error (|train error - test error|). In other words, bigger networks generalize better. [7] This is in contradiction to what traditional complexity metrics such as VC dimension — a metric to quantify the difficulty of learning from examples, have promised. [8]
This theory also challenges a debate about whether or not deep neural networks (DNNs) achieve their performance by memorizing training data or by learning patterns. [9] If they memorize the data, how could they possibly generalize to predict the unseen data? And if they don’t memorize the data but only learn the underlying pattern, how do they predict correct labels even when we introduce a certain amount of noise to the labels?

{kind=link}
Understanding Deep Learning Requires Rethinking Generalization
An interesting paper on this subject is Understanding deep learning requires rethinking generalization [10]. The authors argue that traditional approaches fail to explain why larger networks generalize well and at the same time, these networks can fit even random data.
A notable part of this paper explains the role of explicit regularizations such as weight decay, dropout, and data augmentation on the generalization error:
Explicit regularization may improve generalization performance, but is neither necessary nor by itself sufficient for controlling generalization error. L2-regularization (weight decay) sometimes even helps optimization, illustrating its poorly understood nature in deep learning. [10]
Even with dropout and weight decay, InceptionV3 was still able to fit the random training set very well beyond expectation. This implication is not to devalue regularization, but more to emphasize that bigger gains could be achieved from changing the model architecture.

So what makes a neural network that generalizes well, different from those that generalize poorly? It seems like a rabbit hole. We yet need to rethink a few things:
Our understanding of a model’s effective capacity.
Our measurement of a model’s complexity and size. Are model parameters or FLOPs simply good metrics? Obviously not.
The definition of generalization and how to measure it.

When it comes to big networks and the effect of parameter count on generalization you can find numerous papers and blog posts, some even contradicting others.
Our current understanding could suggest that larger networks can generalize well despite their tendency to overfit. This could be due to their depth, allowing learning of more complex patterns when compared to shallow networks. This is mostly domain-dependant — certain data types may benefit from smaller models and by following Occam’s razor principle.
3. Implicit Regularization in Neural Networks
At the heart of machine learning lies Gradient Descent — the steps we take to find the local minima in a loss landscape. Gradient Descent (GD), along with Stochastic Gradient Descent (SGD) is one of the first that is digested by anyone starting to learn machine learning.
As the algorithm seems straightforward, one might expect that it does not have much depth. However, you can never find the button of the pool in machine learning.
Do neural networks benefit from an implicit regularization by Gradient Descent that pushes them to find simpler and more general solutions? Could this be the reason why over-parametrized networks generalize as shown in the previous part?
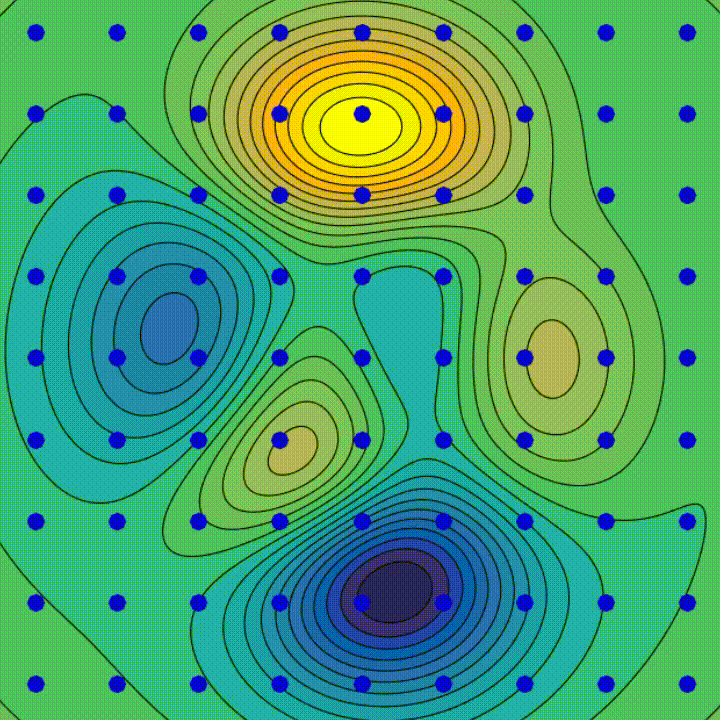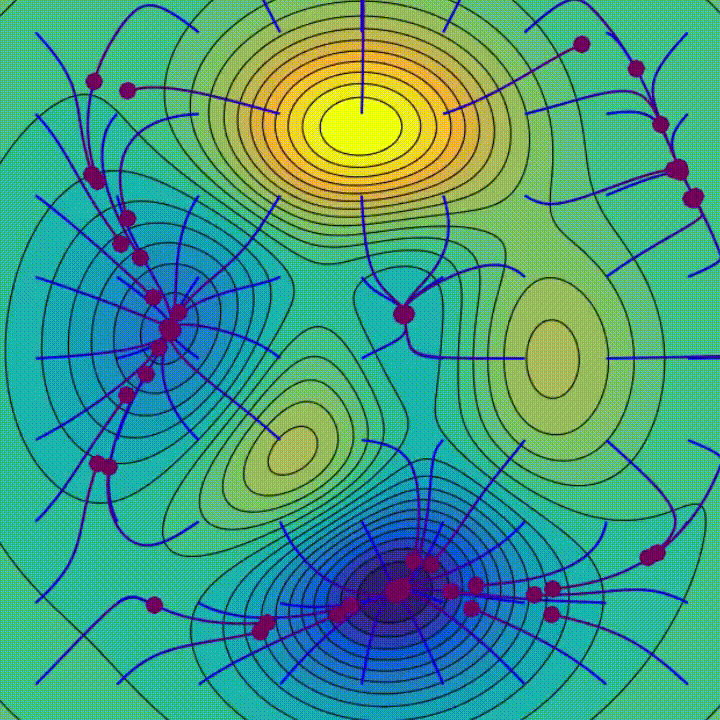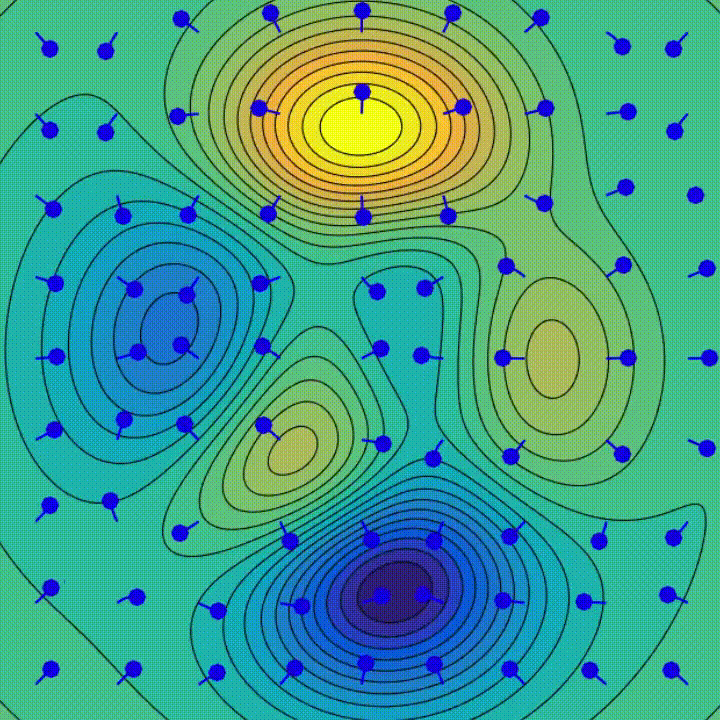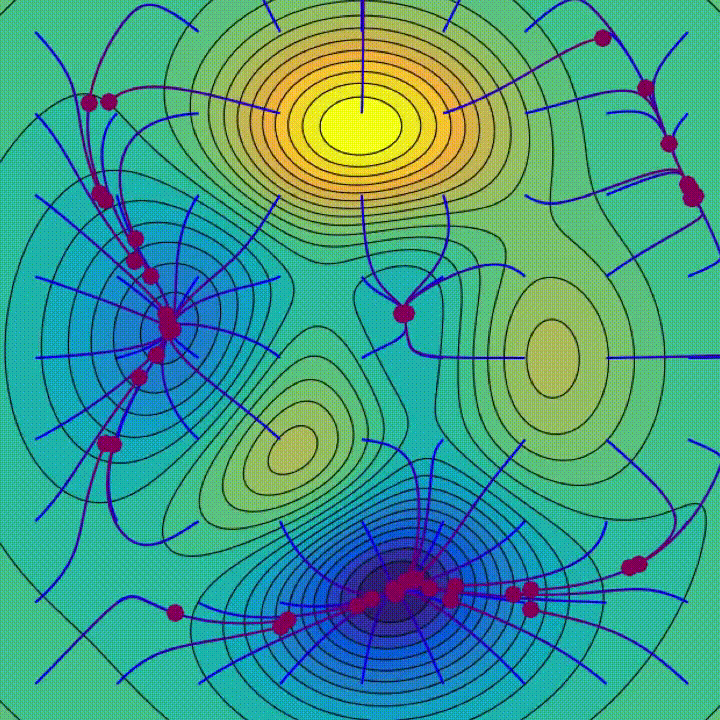
There are two experiments you need to pay close attention to:
Experiment 1
When the authors of [11] trained models on CIFAR-10 and MNIST datasets using SGD and no explicit regularization, they concluded that as the size of the network increases, the test and training errors keep decreasing. This goes against the belief that bigger networks have a higher test error because of overfitting. Even after adding more and more parameters to the network, the generalization error does not increase. Then they forced the network to overfit by adding random label noise. As shown in the figure below, even with 5% random labels, the test error decreases further and there are no significant signs of overfitting.

Experiment 2
An important paper, In Search of the Real Inductive Bias [12], experiments by fitting a predictor using linearly separable datasets. The authors show how logistic regression, using gradient descent and no regularization, inherently biases the solution towards the maximum-margin separator (also known as hard margin SVM). This is an interesting and surprising behavior of gradient descent. Because even though the loss and the optimization don’t directly involve any terms that encourage margin maximization (like those you find in Support Vector Machines), gradient descent inherently biases the solution towards a max-margin classifier.
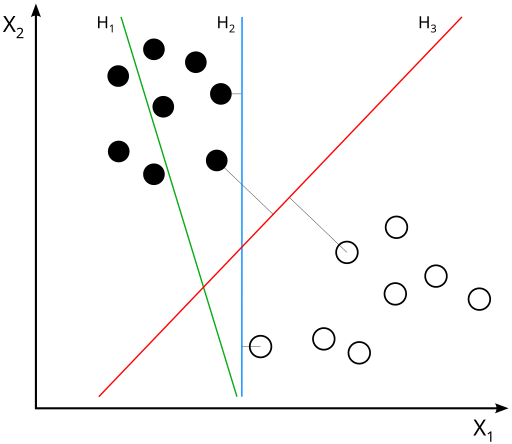
.svg){kind=link}
Gradient Descent as a natural Reguralizer
The experiments suggest an implicit regularization effect as if the optimization process favors simpler and more stable solutions. This implies that GD has a preference for simpler models, often converging to a special type of local minima referred to as “flat” minima, which tends to have lower generalization error compared to sharper minima. This helps explain why deep learning models often perform well on real-world tasks beyond the training data. This suggests that the optimization process itself can be considered a form of implicit regularization, leading to models that are not only minimal in error on the training data, but also robust in their prediction of unseen data. A full theoretical explanation remains an active area of research.
Perhaps this article could also be interesting to you, on how and why deep neural networks are converging into a unified representation of reality:
Are AI Deep Network Models Converging?

A recent MIT paper has come to my attention for its impressive claim: AI models are converging, even across different modalities — vision and language. “We argue that representations in AI models, particularly deep networks, are converging” is how The Platonic Representation Hypothesis
4. The Lottery Ticket Hypothesis
Model pruning can reduce the parameters of a trained neural network by 90%. If done correctly, this could be achieved without dropping the accuracy. But you can only prune your model after it has been trained. If we could manage to remove the excess parameters before training, this would mean using much less time and resources.
The Lottery Ticket Hypothesis [13] argues that a neural network contains subnetworks that when trained in isolation, can reach test accuracy comparable to the original network. These subnetworks — the winning tickets, have the initial weights that make their training successful — the lottery.
The authors find these subnetworks through an iterative pruning method:
Training the Network: First, they train the original unpruned network.
Pruning: After training, they prune p% of the weights.
Resetting Weights: The remaining weights are set to their original values from the initial initialization.
Retraining: The pruned network is retrained to see if it can reach the same or higher performance than the previous network.
Repeat: Until a desired sparsity of the original network is achieved, or the pruned network can no longer match the performance of the unpruned network, this process is repeated.

The proposed method of iterative training is computationally expensive, requiring training a network 15 times or more on multiple experiments.
It remains an area of research why we have such phenomena in neural networks. Could it be true that SGD only focuses on the winning tickets when training the network and not the full body of the network? Why do certain random initializations contain such highly effective sub-networks? If you want to dive deep into this theory, don’t miss out on [13] and [14].
Final Word.
Thank you for reading through the article! I have tried my best to provide an accurate article, however, please share your opinions and suggestions if you think any modifications are required.
Let’s Connect!
Subscribe for FREE to be notified of new articles! You can also find me on LinkedIn and Twitter.
Further Reads
If you have reached so far, you might also find these articles interesting:
Learn Anything with AI and the Feynman Technique

When was the last time you stumbled upon a difficult subject to learn? Or when you spent an hour watching YouTube videos on how to better learn things?
A Comprehensive Guide to Collaborative AI Agents in Practice

Agentic AI is one of the hottest subjects of the AI community in 2024 and there is a good reason for that. Foundational Models are becoming more sophisticated in reasoning and planning. With these capabilities in place, we can leverage LLMs to divide a given task into smaller pieces, perform them step by step, and reflect on thei…
References
[1] Ioffe, S., & Szegedy, C. (2015). Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv.
[2] Outside the Norm, DeepLearning.AI
[3] Santurkar, Shibani; Tsipras, Dimitris; Ilyas, Andrew; Madry, Aleksander (29 May 2018). “How Does Batch Normalization Help Optimization?”. arXiv:1805.11604
[4] Li, H., Xu, Z., Taylor, G., Studer, C., & Goldstein, T. (2018). Visualizing the Loss Landscape of Neural Nets. arXiv
[5] On The Perils of Batch Norm
[6] https://x.com/svpino/status/1588501331316121601
[7] Neyshabur, B., Li, Z., Bhojanapalli, S., LeCun, Y., & Srebro, N. (2018). Towards Understanding the Role of Over-Parametrization in Generalization of Neural Networks. arXiv.
[8] Why is deep learning hyped despite bad VC dimension?
[9] DEEP NETS DON’T LEARN VIA MEMORIZATION
[10] Zhang, C., Bengio, S., Hardt, M., Recht, B., & Vinyals, O. (2017). Understanding Deep Learning Requires Rethinking Generalization. arXiv:1611.03530
[11] Neyshabur, B., Tomioka, R., & Srebro, N. (2015). In Search of the Real Inductive Bias: On the Role of Implicit Regularization in Deep Learning. arXiv:1412.6614
[12] Soudry, D., Hoffer, E., Nacson, M. S., Gunasekar, S., & Srebro, N. (2017). The Implicit Bias of Gradient Descent on Separable Data. arXiv:1710.10345
[13] Frankle, J., & Carbin, M. (2019). The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks. arXiv:1803.03635
[14] https://www.lesswrong.com/posts/Z7R6jFjce3J2Ryj44/exploring-the-lottery-ticket-hypothesis